
Academy
Continuous learning with free, on-demand courses that include easy-to-follow instructions plus tips and tricks.
The heart of our technology is the OpenSpace Spatial AI engine. We launched our proprietary algorithms for the industry based on nearly two decades of combined research and development that started with the founders’ work at MIT. Now, as the market leader in reality capture, spatial computing, and artificial intelligence for builders, OpenSpace continues to improve and deliver powerful, reliable, simple-to-use products.
Computer vision is a field of AI that trains computers to interpret and understand digital images and videos. It’s used in self-driving cars, industrial automation, and robotics, to name a few. OpenSpace’s Spatial AI relies on computer vision to automatically align images into a single integrated scene, recognize and label key features, and map them to floor plans, for a rich, visual understanding of the captured environment.
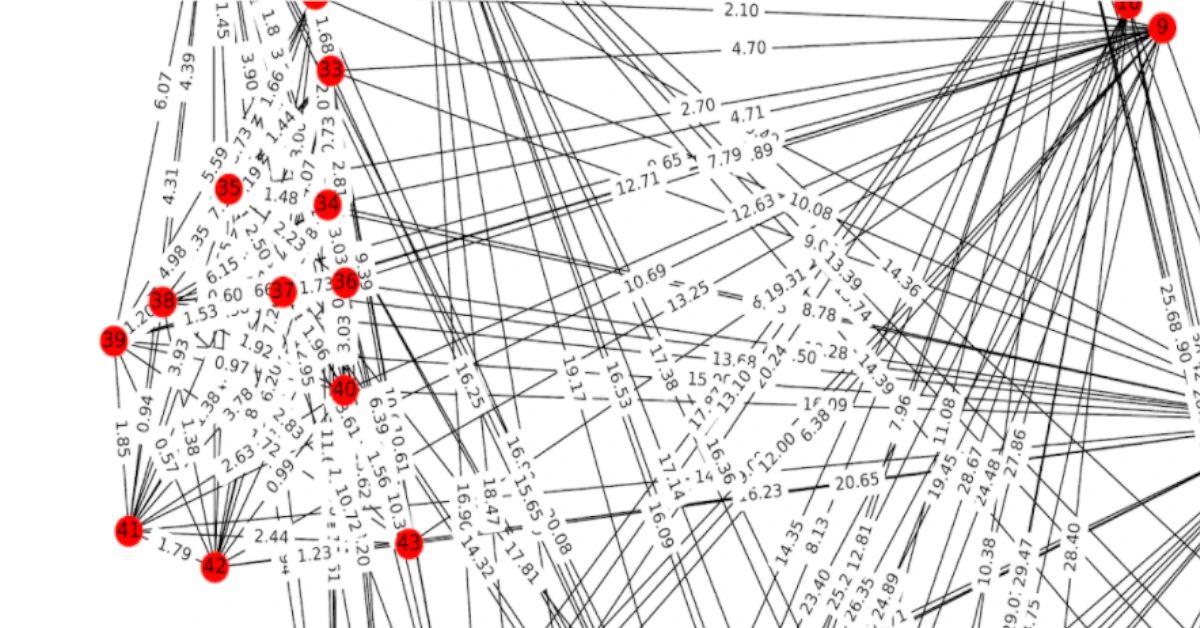
Our Spatial AI uses 3D reconstruction to locate features in space and recreate 3D environments. It compares features in two images, then computes an estimate of camera position that best aligns those features. This process is repeated thousands of times across a full OpenSpace 360° video capture, creating a 3D point cloud. The point cloud ties a feature in an image to a 3D location in space.
Machine learning algorithms create a mathematical model based on training data to predict future results without being explicitly programmed to perform the task. Our AI uses each capture and walk track as a training dataset. Every time you walk the site, the OpenSpace Spatial AI engine learns a bit more about the 3D environment you’re in, aligning and mapping images faster and more accurately.
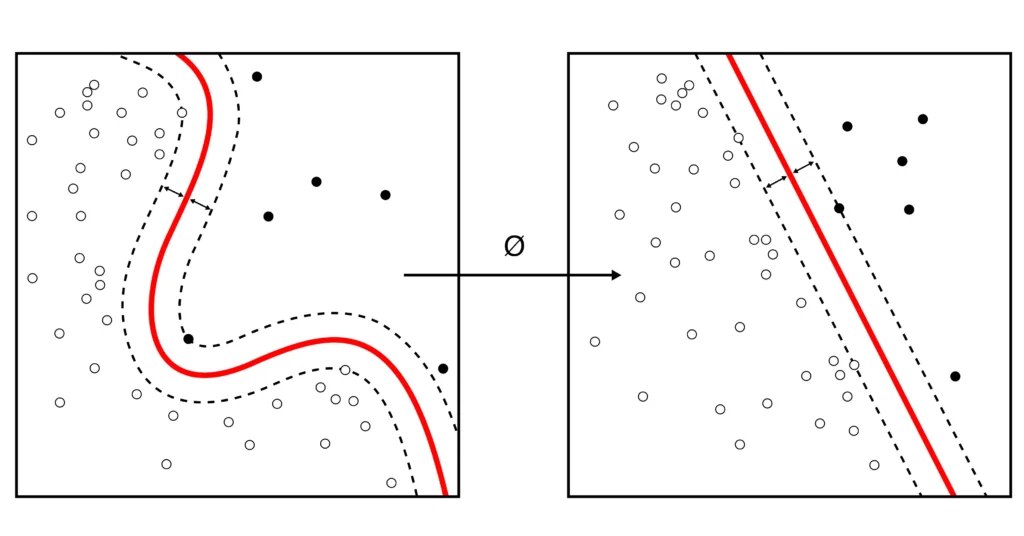
Simultaneous Location and Mapping (SLAM) is a technique to construct a map of an unknown environment while simultaneously moving through it. SLAM is one of the core algorithms used for self-driving car navigation. OpenSpace uses image-based SLAM to estimate the path of the walker on a floor plan, with algorithms constantly aligning sequential data to estimate position and path.
Generative AI is a type of AI that can create new content, such as text, images, music, and more. These large language models are used to power a class of AI assistants or co-pilots that have become popularized by the media and by users of chatbots like ChatGPT. Generative AI works by taking a whole bunch of data, usually from the internet, and crunches through that data, learning how to do specific tasks. OpenSpace is applying large language models to help interpret and provide insight from reality capture data.
“Lots of companies claim to be automated, but this really is. I’m usually really skeptical of people who come out with construction tech, because a lot of us are set in our ways. But then they showed me the software and it blew me away."

OpenSpace collects data from 360° images, mobile phone photos, drone imagery, and laser scans across your projects. Our Spatial AI engine turns that reality data into insights to help you quickly find answers and make better decisions.
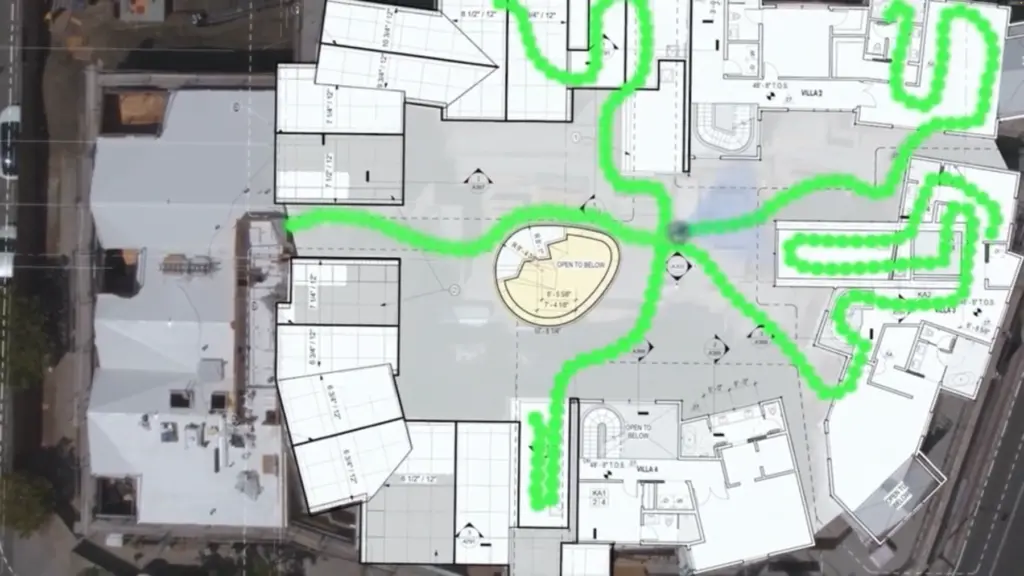
With OpenSpace Capture, our Spatial AI engine stitches images together and pins them to your floor plan, creating a comprehensive and shared visual record of your jobsite.


