OpenSpace Vision Engineは、画像を現実のキャプチャにすることを自動化します。
コンピュータビジョンでデジタル画像の意味を理解するAI
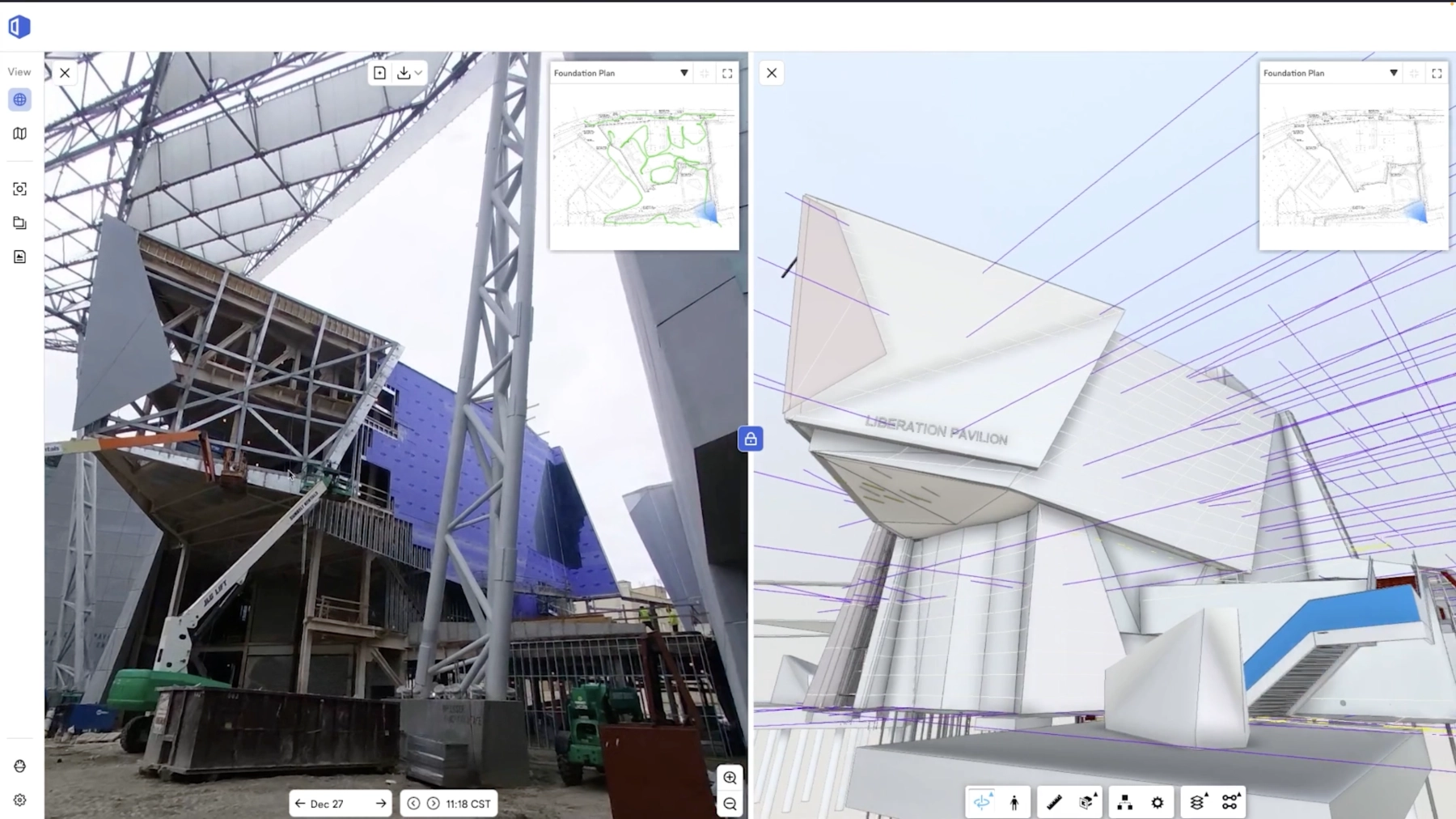
コンピュータビジョンは、デジタル画像や動画を解釈し理解するためにコンピュータを訓練するAIの一分野です。自動運転車、産業用オートメーション、ロボット工学などで使用されています。OpenSpaceのVision Engineは、コンピュータビジョンを利用して、画像を自動的に1つの統合されたシーンに整列させ、主要な特徴を認識しラベル付けし、フロアプランにマッピングすることで、撮影した環境を視覚的に豊かに理解できるようにします。
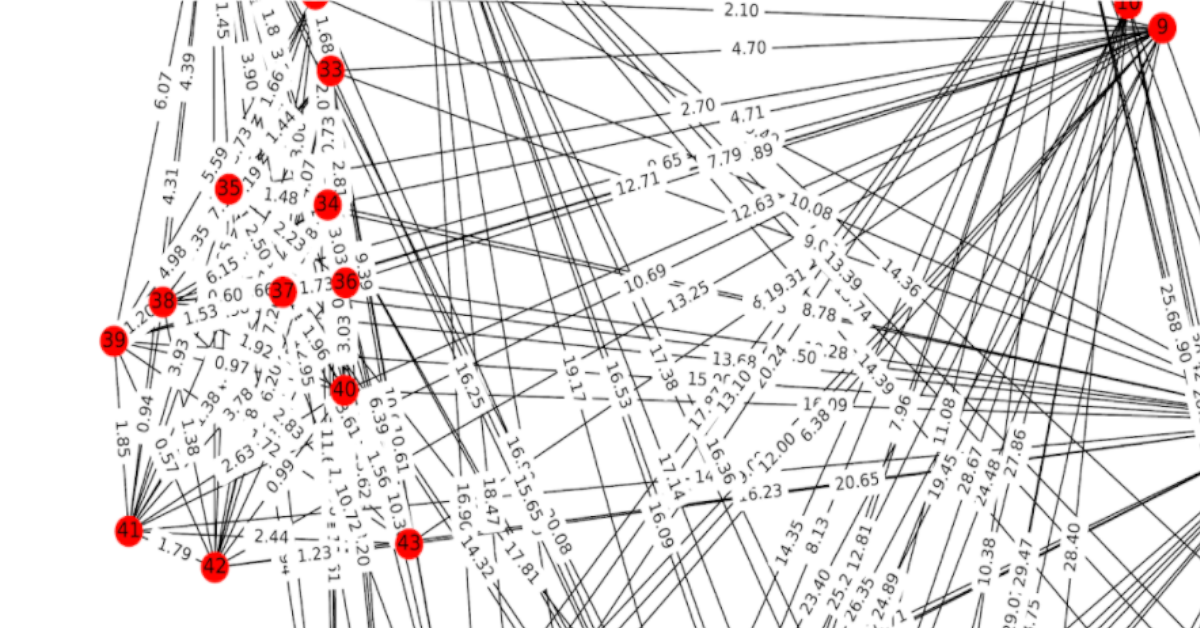
3D再構成:3D点群の作成
ビジョンエンジンは、3D再構成により、空間内の特徴を見つけ、3D環境を再現します。2つの画像の特徴を比較し、それらの特徴を最もよく配置するカメラ位置の推定値を計算します。このプロセスは、OpenSpaceの360°ビデオキャプチャ全体で何千回も繰り返され、3Dポイントクラウドが作成されます。点群によって、画像内の特徴と空間内の3Dロケーションが結びつけられます。

機械学習:Vision Engineをよりスマートに
機械学習アルゴリズムは、トレーニングデータに基づいて数学的モデルを作成し、タスクを実行するように明示的にプログラムされることなく、将来の結果を予測します。ビジョンエンジンは、各キャプチャとウォークトラックをトレーニングデータセットとして使用します。あなたが現場を歩くたびに、Vision Engineはあなたがいる3D環境について少しずつ学習し、より速く、より正確に画像の位置合わせとマッピングを行います。
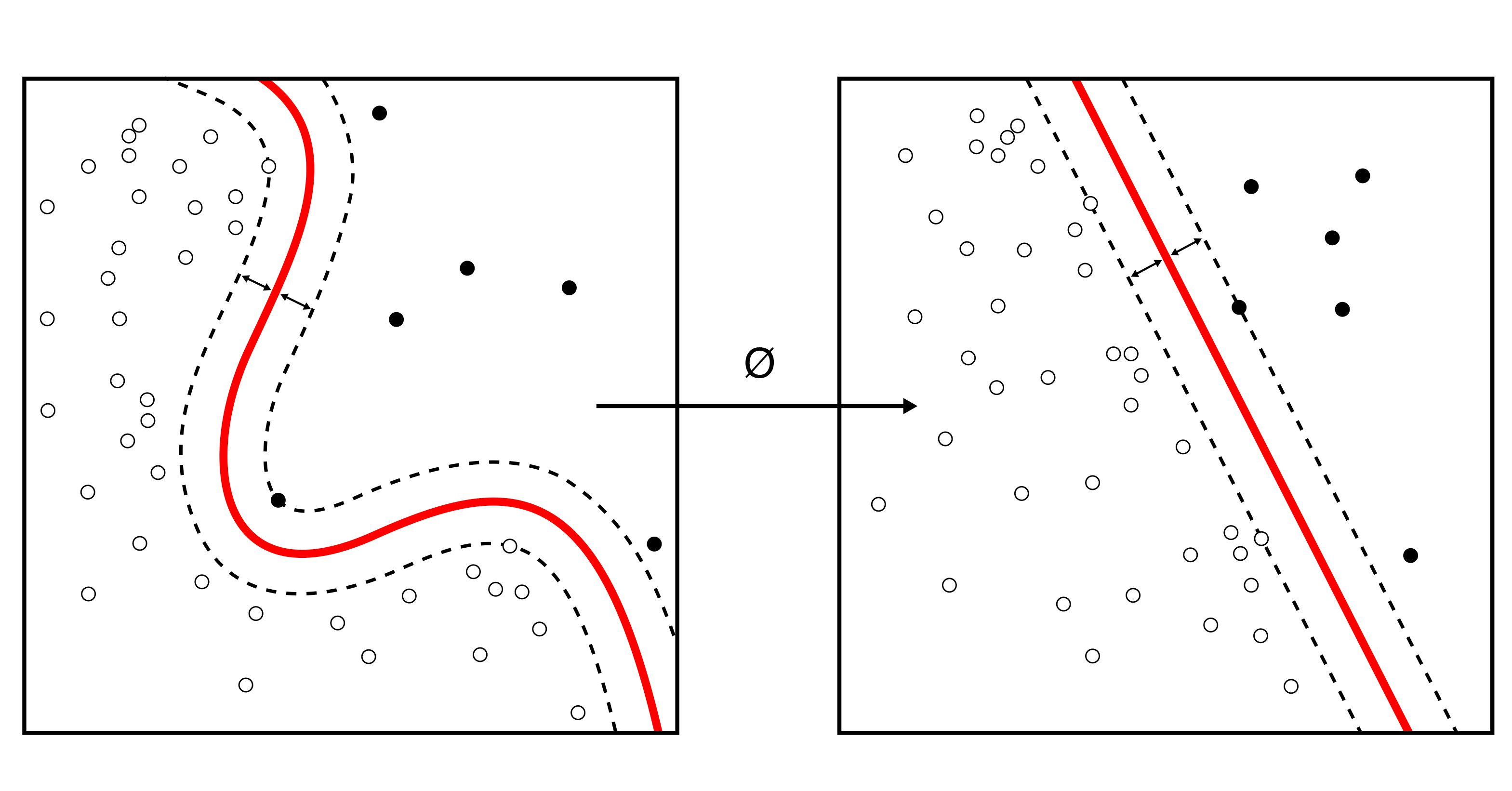
SLAM: 画像の位置合わせ
SLAM(Simultaneous Location and Mapping)とは、未知の環境を移動しながら同時に地図を構築する技術である。SLAMは、自動運転車のナビゲーションに使われるコアアルゴリズムの一つです。OpenSpaceでは、画像ベースのSLAMを用いて、平面図上の歩行者の経路を推定し、アルゴリズムが連続したデータを常に整列させて位置と経路を推定しています。
もっと詳しく知りたいですか?
OpenSpace 360°リアリティキャプチャを実際にご覧ください。
高度な分析機能で画像からインサイトを得る

セマンティックセグメンテーション:画像をメトリクスに変換する
セマンティックセグメンテーションとは、画素を論理的な塊にグループ化するプロセスで、例えば、黄色のシャツの画素と赤いスカーフの画素を区別することができます。OpenSpaceでは、セマンティックセグメンテーションを利用して、建設業に特化したクラスと分類器を開発し、生画像を追跡・カウント可能な論理的セグメントに変換しています。
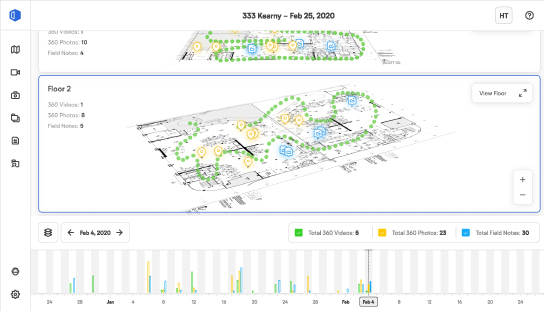
プログレス・トラッキング:画像ベースのメトリクスを経時的に数値化する
画像処理、位置合わせ、位置決め、セグメンテーションを行った後、画像を解析し、進捗状況を把握することができます。オブジェクト検出を使用して配置されたアイテムや、セマンティックセグメンテーションを使用して分類されたアイテムは、点群を使って3D空間に配置され、時間経過とともに追跡されることができます。その結果、プロジェクト活動の定量的なマップができあがり、OpenSpaceは、作業現場の確認、取引の調整の維持、生産性のベンチマークに使用します。
ビッグデータの可視化:分析基盤を提供する
ビッグデータの可視化とは、大規模で複雑なデータセットを視覚的に表現し、消化・理解しやすくすることです。OpenSpaceには、革新的なビジュアライゼーションを開発してきた長い歴史があります。このTED Talk では、MITの研究者が、乳児の息子が新しい言葉をいつどうやって覚えたかを理解するために、9万時間のホームビデオを録画した方法を説明しています。この講演では、当時彼の学生であった私たちの創設者たちの仕事が紹介されています。
「自動化を謳う企業は他にもたくさんあるが、OpenSpaceは本当に自動化されています。私たちの多くは自分のやり方に固執していたが、OpenSpaceのソフトウェアを見たとき、私たちは圧倒されました」
ティム・クロフォード監督
こうな技術で作られたシンプルで使いやすいツール
初めての完全自動化リアリティキャプチャ
OpenSpace Captureでは、Vision Engineが画像をつなぎ合わせてフロアプランにピン留めし、現場の包括的で共有可能なビジュアル記録を作成します。
完了した作業を自動的に測定するAI
OpenSpace Trackは、Vision Engineからの画像ベースのデータを使用して、乾式壁、機械、電気などのセグメンテーション、分類、進捗状況の追跡を行います。